
Leveraging Foundational Models for Metadata Extraction and Beyond
September 12, 2023
Art Morales

In recent years, the data and AI community has witnessed a rapid emergence of foundational models, often referred to as large language models (LLMs). These models have unlocked new frontiers in handling and extracting insights from data and text contained in unstructured documents and other sources. These documents, be it in the form of research papers, legal contracts, or even blogs, contain a wealth of information and knowledge.
This has led to almost every company we talk to having initiatives to “Put an LLM on top of our documents and build a chatbot”.
To a large extent, this is positioned as the “killer app” and may often provide the consumer of content with significant value through minimal investment. Not only that, but an LLM endpoint can often be a great complement to traditional enterprise search applications to improve findability and re-use of data and content.
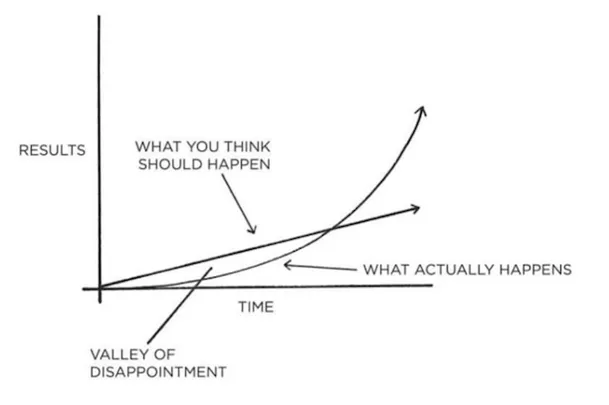
However, just putting a language model on top of a corpus is not a panacea. As statistical models (albeit very good ones), GenAI applications bring with them unpredictability and variability in their responses. Prompt engineering quickly emerged as an approach to get better outputs, but it doesn’t solve all problems. The user experience of using a chatbot to interrogate documents thus depends not only on the prompt literacy of the user, but also on the statistical model behind the scenes and context of the document. This often results in a valley of disappointment where the expectations don’t quite match the results once users dig deeper into the documents.
One of the most promising approaches to complement the chat experience is to use foundational models to extract metadata from documents in parallel and store them in traditional and/or graph databases.
In this approach, documents are pre-processed through a series of standard prompts designed to extract certain metadata fields and relationships from each document. These fields are stored in a traditional database to be used with search and data mining techniques. During the extraction, checks can be put in place to identify extraction failures and these documents can be further analyzed by other methods and/or curation teams to confirm if the information exists or not in those documents.
Using Foundational Models to extract metadata has many benefits over traditional NLP approaches; Among them:
Precision and Recall: With their vast training datasets and immense capacity, LLMs can identify and extract metadata with high accuracy. They capture both the explicit details mentioned in the text and the implicit connections. These implicit connections can be used to feed a graph model and enhance data mining.
Versatility: From named entities like company names, dates, and locations to more abstract concepts like sentiments or themes, LLMs can extract a wide array of metadata.
As mentioned above, once metadata is extracted, it can be a goldmine for various data science applications that are more deterministic:
Trend Analysis: Using extracted metadata, we can detect emerging trends, patterns, and shifts over time in vast corpora of documents. By implementing checks during the metadata extraction, to identify where it fails and where it can be improved, we can increase the confidence in the results, as opposed to leaving it to the model to decide on the spot.
Semantic Search: Improve search capabilities by indexing and retrieving documents based on their extracted metadata, leading to more contextually relevant search results. Combining this approach with the ability to interrogate documents in a chatbot can then provide the most accurate and complete experience.
Minimizing Hallucinations: Results from Foundational Model chats can be easily checked against the extracted metadata to improve confidence in the outputs.
One exciting area of innovation in the field deals with using Graph Databases like Neo4J or Amazon Neptune. These databases store data in nodes and edges, representing entities and their relationships, respectively. Metadata extracted using LLMs provides rich content for such databases:
Relationship Mapping: For example, if two research papers mention similar entities and concepts, there might be a relationship or a thematic overlap. By feeding this metadata into a graph database, we can identify and visualize these connections.
Knowledge Graphs: Knowledge graphs can be built or enhanced using metadata. These graphs can represent complex relationships among various entities, aiding in more intuitive data exploration.
Graph-Based Querying: With the enriched metadata, querying a graph database becomes more powerful. It’s possible to traverse through connected entities to derive insights or make predictions about unexplored relationships. Use cases such as similarity, anomaly detection, communities, and networks of related data entities (such as a social graph for Investigators as an example use case).
Informing Other Types of Querying This is an exciting area of research. Because we know the relationships between objects, Graph models can be included during foundational model prompting to help guide the Generative AI output and potentially provide more relevant and insightful results.
While the synergy between chatbots and LLM-driven metadata extraction is evident, it’s important to be aware of potential pitfalls such as bias and non-deterministic behavior but combining the two can provide significantly better and more accurate results than just using a chatbot or digital advisor.
It is also important to consider the security and privacy implications of using 3rd party Language Model APIs. Although it is possible to host smaller models internally, the most informative and productive language models still require a large amount of compute power and thus we often rely on external systems to process prompts and embeddings. The good news is that recent offerings from OpenAI, AWS, Microsoft, Databricks and Snowflake, to name a few, are improving the security and regulatory landscape. Nevertheless, cutting-edge innovation is often filled with known and unknown risks in this space. The directed knowledge extraction approach introduced here helps to mitigate some of the risks to data accuracy and quality, but we must not forget the rest of the data ecosystem and associated risks. We will discuss additional risk mitigation strategies in future posts.