
Narrativized Embeddings: Bridging Structured Data and Semantic Understanding
May 23, 2025
Art Morales, Ph.D

In data science and artificial intelligence, effectively extracting and utilizing semantic relationships from structured data is crucial. Traditional methods like knowledge graphs are powerful but may be resource-intensive to develop and maintain. An alternative approach, termed "narrativized embeddings," offers a practical solution by converting structured data into narratives, using templates to describe structured data and their relationships in an agile manner, thereby enhancing semantic comprehension and facilitating advanced applications such as retrieval-augmented generation (RAG) in conversational AI systems.
Concept Overview
Narrativized embeddings are not restricted to a single sentence. They can encompass entire paragraphs, sections, or even documents derived from larger records, even shifting from record-level details to domain-level narratives. For instance, an electronic medical record (EMR) can be narrativized into a long document that describes a patient's history, mimicking the structure and details found in traditional records. Once standardized, such records can be chunked into manageable segments, vectorized, and stored in a database. This approach ensures that related fields or measures are placed in proximity, enhancing the ease of retrieval and contextual understanding.
By chunking and vectorizing, the embeddings allow for context-aware searches, ensuring that queries retrieve relevant and comprehensive results. Post-retrieval ranking can further refine the results, identifying and prioritizing embeddings with strong interrelatedness or high relevance to the query context.
For example, one can take related tables describing results from lead development in a pharmaceutical company like the ones below:
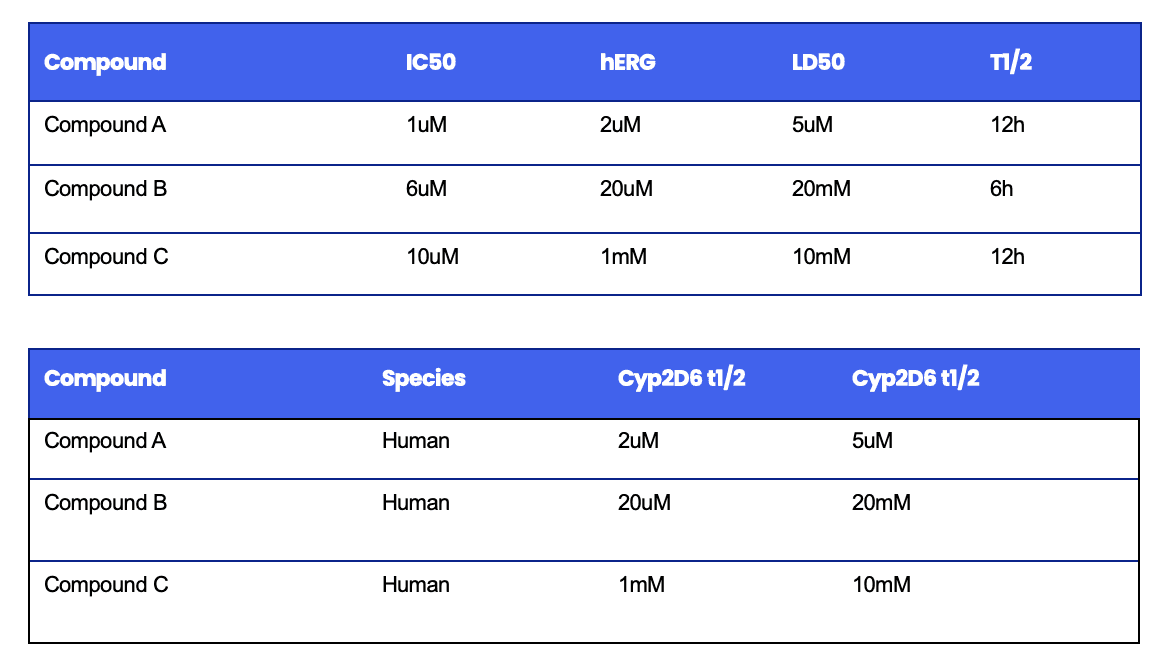
And use a template like this one:
<Compound> inhibited <Target> at a concentration of <IC50>, with a half-life of <t1/2> in <species> when administered <route>. It inhibited hERG at a concentration of <hERG> and shows a toxicity (LD50) of <LD50> in <species>
to generate one sentence per row and then create embeddings. Note that the template includes other fields such as species and route that may be part of a separate table. The template handles the embedding of the semantic meanings into the narrative.
One benefit for this approach is that multiple templates can be built to capture different sections/connections within the structured dataset. For example, another template could be defined that created narratives for compounds focused only on the in vitro results:
<Compound> inhibited <Target> at a concentration of <IC50>, with a half-life of <t1/2> in <species> liver microsomes and half-life of <Cyp2D6 t1/2> in Cytochrome P450 2D6, <Cyp3A4 t1/2> in Cytochrome P450 3A4.
An agent can then be used to choose the right template to search embeddings against as a pre-filter before searching the vector database.
Although it takes time to generate these templates and find the connections, these can be built on top of existing databases without the need to remodel data, providing flexibility during insight discovery without having to fully invest in a knowledge graph and in many cases, can help an organization get started into their semantic and graph journeys.
In-Depth Look at Narrativized Embeddings
Narrativized embeddings involve transforming each row of a structured database into a coherent narrative that encapsulates the data's inherent semantics. This process includes:
• Template-Based Narrative Generation: Utilizing predefined templates, each database entry is converted into a narrative that not only describes the data but also integrates information from related tables. This integration highlights semantic relationships that may not be immediately apparent from SQL column descriptions alone.
• Embedding Conversion: The generated narratives are transformed into vector embeddings. These embeddings serve as dense, numerical representations of the narratives, capturing their semantic essence.
• Vector Search and RAG Integration: The embeddings facilitate efficient vector searches, enabling the retrieval of semantically relevant information. In RAG systems, these embeddings can be used to provide contextually appropriate responses, enhancing the system's ability to generate accurate and relevant outputs.
Advantages
Comprehensive Representation of Complex Records: Narrativized embeddings enable the conversion of large, complex records like EMRs into detailed narratives. These narratives preserve the integrity of the data and provide a standardized format that facilitates advanced querying and analysis.
Narratives disambiguate the connections between data from disparate sources in context. This reduces redundancy and improves reliability of insights.
This approach also allows for grouping related fields or measures in close proximity, making them more accessible and contextually relevant during searches.
Enhanced Post-Retrieval Ranking: After retrieving embeddings, ranking mechanisms can be applied to identify the most related narratives and even identify other narrative templates to search. This ensures that searches return not only relevant results but also highlight connections among related data points.
Quick Idea Testing and Development: Narrativized embeddings enable rapid iteration and development without committing to building a full knowledge graph. This flexibility allows teams to test hypotheses, refine templates, and explore new questions without requiring an in-depth understanding of the modeled domain. Consider using nanopublication formats to enable future integrations.
Enhanced Semantic Relationships: By narrativizing data, implicit connections within the data become explicit, improving comprehension and analysis.
Resource Efficiency: This method offers a viable alternative to building comprehensive knowledge graphs, which can be resource-intensive and require specialized knowledge of Cypher, SPARQL, GraphQL and other graph query languages.
Improved AI Performance: Incorporating narrativized embeddings into AI systems, particularly those utilizing RAG, can lead to more accurate and contextually relevant responses.
Scalability and Flexibility: Narrativized embeddings can evolve alongside the system’s requirements. Basic templates can be expanded to include more complex relationships, or new templates can be developed to address specific needs. This adaptability supports agile development and iterative improvements.
Implementation Considerations
Defining Templates Properly:
Entity Naming: Ensure that entity names are clearly defined and included in the narratives. This distinction is critical for differentiating between embeddings. Begin to introduce URIs and standardize on semantics. Maintain FAIR principles (Findable, Accessible, Interoperable, Repeatable). Plan for success and future interoperability.
Understanding Relationships: Begin with templates that use a basic set of relationships and gradually expand to incorporate deeper or more specific connections. Multiple templates can cater to various facets of the data, such as general overviews versus in-depth analyses.
Handling Negative Embeddings: Negative embeddings can be used to define relationships that are invalid or disallowed. This adds a layer of sanitization and guardrails, ensuring that the system avoids incorrect interpretations or queries.
Iterative Development:
Start with simple templates and refine them over time. As your understanding of the data improves, templates can be updated to capture more nuanced relationships or to address specific aspects of the process.
Agile practices can be applied to narrative development, allowing embeddings to be optimized incrementally.
Narrativized Embeddings as an Alternative to Knowledge Graphs and an improvement over Text2SQL approaches
Building reliable Retrieval-Augmented Generation (RAG) systems on complex data is essential to democratize access to information, enabling users to query diverse datasets without requiring specialized data science skills. Two prominent approaches to implementing RAG systems for structured data are Text2SQL and Knowledge Graphs, each with distinct strengths and limitations.
Knowledge graphs excel at modeling relationships between entities, offering a rich semantic representation of data. For example, a patient's encounters, diagnoses, and observations can be interconnected, enabling queries like, "What conditions were observed in Patient X's last two encounters?" However, building and maintaining a knowledge graph can be a resource-intensive process and requires investing in semantics and governance. To be clear, these investments are well-worth the efforts, but unless a knowledge graph already exists, creating one requires significant expertise, domain knowledge, and ongoing maintenance to remain accurate and up-to-date.
Text2SQL, on the other hand, translates natural language queries into SQL statements, offering an effective solution for querying structured databases. For instance, if a user asks, "What is the most recent blood pressure reading for Patient X?" Text2SQL generates a SQL query to retrieve the relevant record directly from the database. While well-suited for simple, straightforward queries, Text2SQL faces limitations when handling complex queries that demand domain-level reasoning or integration of data from multiple sources. For example, a query like "Summarize Patient X's medical history over the past year, including key conditions, treatments, and trends" involves aggregating data across multiple tables (e.g., Encounter, Condition, Observation) and constructing a cohesive narrative—something beyond the capabilities of basic Text2SQL systems, especially as when the columns and their relationships are not well described.
Narrativized Embeddings: A Flexible Approach to Semantic Contextualization
Narrativized embeddings excel in their adaptability to diverse topics and queries. For example, you can create narrativized embeddings for toxicology while using the same dataset—or a subset of it—for pharmacokinetics (PK) or absorption, distribution, metabolism, and excretion (ADME). This allows agents or question embeddings to match user queries against vector templates, dynamically selecting the most relevant data subset for retrieval. The result is highly contextual and accurate retrieval with minimal manual effort.
While knowledge graphs are ideal for unequivocally defining relationships and solving relational modeling challenges, narrativized embeddings shine in exploratory contexts where relationships or queries may not be fully understood and the questions are simpler.
Where Narrativized Embeddings Fit In
Narrativized embeddings can adapt to diverse topics and queries. By building multiple templates to represent different relationships or facets of the data, these embeddings enable agile and contextually rich retrieval. The primary effort lies in crafting templates, and once defined, generating narratives and embeddings can be fully automated. Narrativized embeddings thus serve as a practical middle ground:
More agile and less resource-heavy than building a full knowledge graph.
More semantically rich and context-aware than basic Text2SQL approaches.
They are particularly valuable in exploratory contexts or where complex relationships are not fully understood, allowing for flexible and incremental development.
Combining Narrativized Embeddings with Knowledge Graphs
Narrativized embeddings are not limited to scenarios lacking a knowledge graph; in fact, they can be effectively generated from existing knowledge graphs. This integration allows for the direction of specific relationships and the application of language-driven context to support RAG systems.
By deriving narrativized embeddings from a knowledge graph, one can leverage the explicit relationships and structured information inherent in the graph. This process involves creating narrative templates that reflect the graph's connections, which are then transformed into embeddings. These embeddings encapsulate both the structured knowledge and the contextual richness of natural language, enhancing the retrieval and generation capabilities of AI systems.
Integrating narrativized embeddings with knowledge graphs is particularly beneficial in complex domains where relationships are intricate and multifaceted. The combination enables systems to utilize the precise, structured data from knowledge graphs alongside the inferential strengths of language models processing narrativized embeddings. This synergy facilitates more accurate and contextually relevant responses in RAG applications.

Narrativized embeddings are versatile tools that can be employed independently or in conjunction with knowledge graphs. They provide flexibility and depth in semantic understanding, enhancing the performance of RAG systems by combining structured data with the contextual nuances of narrative forms.
Comparative Overview: Text-to-SQL, Narrativized Embeddings, and Knowledge Graphs
Below is a comparative overview of three methodologies for utilizing structured data in Retrieval-Augmented Generation (RAG): Text-to-SQL, Narrativized Embeddings, and Knowledge Graphs.

Use Cases and Practicality
In scenarios like RAG and data-driven questioning, a comprehensive solution might be seen as building a knowledge graph for deterministic semantics. On the opposite end, querying raw data relies heavily on the accuracy of text-to-SQL translations. Narrativized embeddings offer a practical middle ground:
Simplified Querying Process: Pre-integrated narratives eliminate complex SQL joins, making queries more intuitive and human-readable.
Improved Performance: Embedding databases optimize vector searches for speed and scalability.
Contextual Insights: Narratives carry contextual information, uncovering implicit connections and reducing ambiguity.
Dynamic Template Selection: Generative AI agents can select the most relevant templates, ensuring contextual and high-quality responses.
Key Advantages of Narrativized Embeddings
Although Narrativized Embeddings do not solve every problem, they can play a major role in multi-agent RAG systems and/or simplify agile chatbot development without major data engineering efforts:
Agility and Scalability
Narrativized embeddings enable flexible semantics and relationships. While they lack a centralized language or relationship-focused structure (as seen in knowledge graphs), templates can provide a degree of standardization. Relationships can also be extracted later as understanding evolves, making this approach a lightweight and effective bridge between raw data querying and full-scale knowledge graph implementations.
Semantic Richness
Positioned between deterministic knowledge graphs and raw SQL queries, narrativized embeddings offer richer semantics and contextual detail. By structuring data into coherent narratives, they enhance query accuracy and relevance without requiring the extensive setup of a knowledge graph.
Strength in Complexity
Knowledge graphs define explicit relationships and ensure precise answers but it can be hard to model complex/nuanced semantics in an ontology that are easier in language. LLMs can capture this, as can a talented ontologist, when available. Narrativized embeddings leverage large language models (LLMs) to infer implicit relationships and uncover insights from linguistic patterns and connections, outperforming knowledge graphs in such scenarios.
Narrativized embeddings present a practical and efficient approach to enhancing semantic understanding in structured data. By converting structured tables into narrative forms with context and transforming these narratives into embeddings, this method facilitates advanced applications like RAG in conversational AI systems. Proper template design, iterative development, and leveraging negative embeddings for guardrails further enhance the system’s flexibility and accuracy.
Whether used independently or integrated with existing knowledge graphs, narrativized embeddings strike a balance between the agility and richness of natural language representations and the structured, well-defined semantics of graph-based data models. This approach offers a robust alternative to traditional knowledge graphs and Text2SQL-based querying, supporting agile development, scalability, and resource-efficient performance in complex, evolving data ecosystems.